I/O多路复用
select poll, epoll区别
目前支持I/O多路复用的系统调用有select,pselect,poll,epoll。与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间
select缺陷:
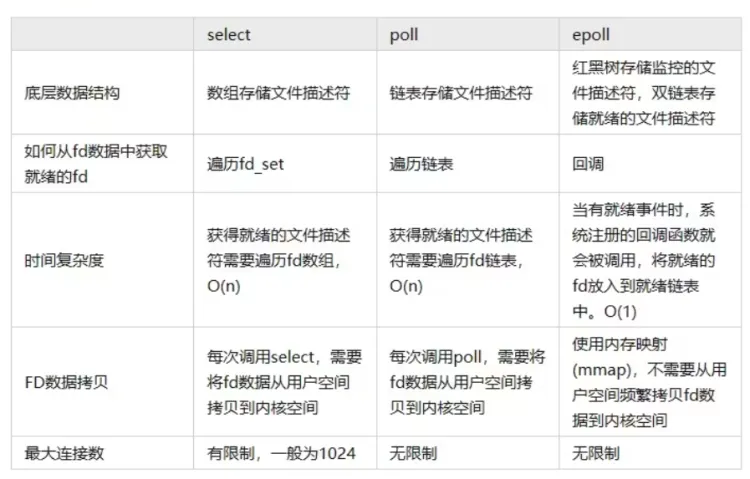
[1] 每次调用select,都需要把被监控的fds集合从用户态空间拷贝到内核态空间,高并发场景下这样的拷贝会使得消耗的资源是很大的。
[2] 能监听端口的数量有限,单个进程所能打开的最大连接数由FD_SETSIZE宏定义,监听上限就等于fds_bits位数组中所有元素的二进制位总数,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上为3264),当然我们可以对宏FD_SETSIZE进行修改,然后重新编译内核,但是性能可能会受到影响,一般该数和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认1024个,64位默认2048。
[3] 被监控的fds集合中,只要有一个有数据可读,整个socket集合就会被遍历一次调用sk的poll函数收集可读事件:由于当初的需求是朴素,仅仅关心是否有数据可读这样一个事件,当事件通知来的时候,由于数据的到来是异步的,我们不知道事件来的时候,有多少个被监控的socket有数据可读了,于是,只能挨个遍历每个socket来收集可读事件了。
poll
poll的实现和select非常相似,只是描述fd集合的方式不同。针对select遗留的三个问题中(问题(2)是fd限制问题,问题(1)和(3)则是性能问题),poll只是使用pollfd结构而不是select的fd_set结构,这就解决了select的问题(2)fds集合大小1024限制问题。但poll和select同样存在一个性能缺点就是包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
struct pollfd {
int fd; /*文件描述符*/
short events; /*监控的事件*/
short revents; /*监控事件中满足条件返回的事件*/
};
int poll(struct pollfd *fds, unsigned long nfds, int timeout);epoll
epoll的边缘触发与水平触发
水平触发(LT)
关注点是数据是否有无,只要读缓冲区不为空,写缓冲区不满,那么epoll_wait就会一直返回就绪,水平触发是epoll的默认工作方式。
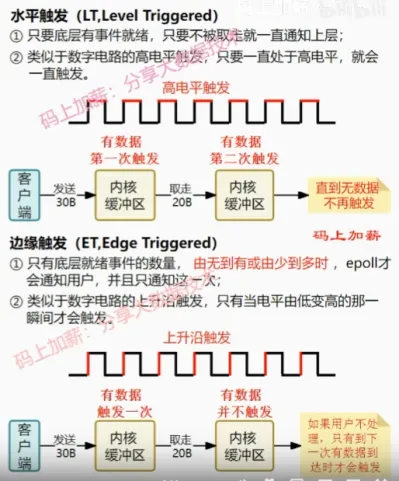
边缘触发(ET)
关注点是变化,只要缓冲区的数据有变化,epoll_wait就会返回就绪。
这里的数据变化并不单纯指缓冲区从有数据变为没有数据,或者从没有数据变为有数据,还包括了数据变多或者变少。即当buffer长度有变化时,就会触发。
假设epoll被设置为了边缘触发,当客户端写入了100个字符,由于缓冲区从0变为了100,于是服务端epoll_wait触发一次就绪,服务端读取了2个字节后不再读取。这个时候再去调用epoll_wait会发现不会就绪,只有当客户端再次写入数据后,才会触发就绪。
这就导致如果使用ET模式,那就必须保证要「一次性把数据读取&写入完」,否则会导致数据长期无法读取/写入。
epoll 为什么比select、poll更高效?
epoll 采用红黑树管理文件描述符
从上图可以看出,epoll使用红黑树管理文件描述符,红黑树插入和删除的都是时间复杂度 O(logN),不会随着文件描述符数量增加而改变。
select、poll采用数组或者链表的形式管理文件描述符,那么在遍历文件描述符时,时间复杂度会随着文件描述的增加而增加。epoll 将文件描述符添加和检测分离,减少了文件描述符拷贝的消耗
select&poll 调用时会将全部监听的 fd 从用户态空间拷贝至内核态空间并线性扫描一遍找出就绪的 fd 再返回到用户态。下次需要监听时,又需要把之前已经传递过的文件描述符再读传递进去,增加了拷贝文件的无效消耗,当文件描述很多时,性能瓶颈更加明显。
而epoll只需要使用epoll_ctl添加一次,后续的检查使用epoll_wait,减少了文件拷贝的消耗。