YUV格式
颜色,亮度和我们的眼睛
我们的眼睛对亮度比对颜色更敏感,你可以看看下面的图片自己测试。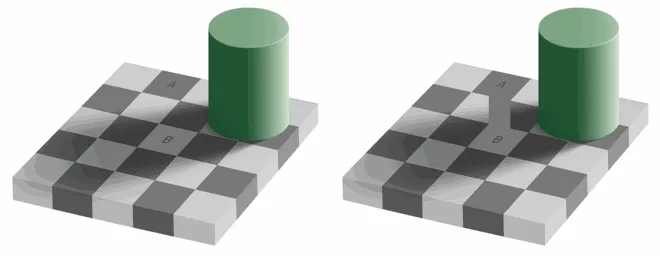
如果你看不出左图的方块 A 和方块 B 的颜色是相同的,那么好,是我们的大脑玩了一个小把戏,这让我们更多的去注意光与暗,而不是颜色。右边这里有一个使用同样颜色的连接器,那么我们(的大脑)就能轻易分辨出事实,它们是同样的颜色。
简单解释我们的眼睛工作的原理
眼睛是一个复杂的器官,有许多部分组成,但我们最感兴趣的是视锥细胞和视杆细胞。眼睛有大约1.2亿个视杆细胞和6百万个视锥细胞。
简单来说,让我们把颜色和亮度放在眼睛的功能部位上。视杆细胞主要负责亮度,而视锥细胞负责颜色,有三种类型的视锥,每个都有不同的颜料,叫做:S-视锥(蓝色),M-视锥(绿色)和L-视锥(红色)。
既然我们的视杆细胞(亮度)比视锥细胞多很多,一个合理的推断是相比颜色,我们有更好的能力去区分黑暗和光亮。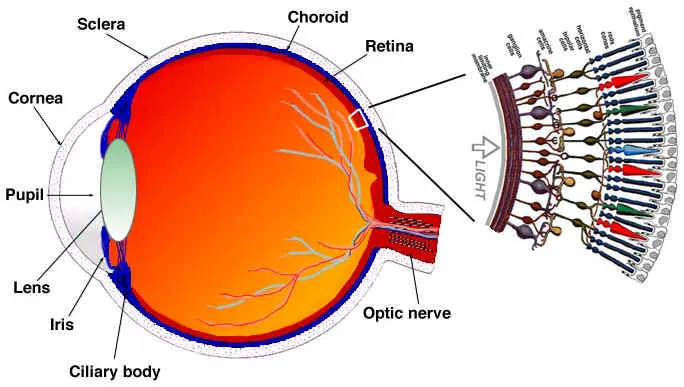
一旦我们知道我们对亮度(图像中的亮度)更敏感,我们就可以利用它。
颜色模型
我们最开始学习的彩色图像的原理使用的是 RGB 模型,但也有其他模型。有一种模型将亮度(光亮)和色度(颜色)分离开,它被称为 YCbCr*。
* 有很多种模型做同样的分离。
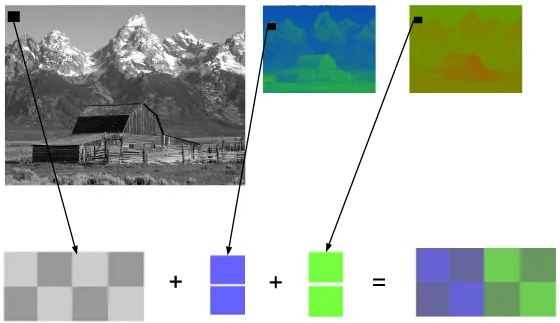
这个颜色模型使用 Y 来表示亮度,还有两种颜色通道:Cb(蓝色色度) 和 Cr(红色色度)。YCbCr 可以由 RGB 转换得来,也可以转换回 RGB。使用这个模型我们可以创建拥有完整色彩的图像,如下图。
YCbCr 和 RGB 之间的转换
有人可能会问,在 不使用绿色(色度) 的情况下,我们如何表现出所有的色彩?
为了回答这个问题,我们将介绍从 RGB 到 YCbCr 的转换。我们将使用 ITU-R 小组*建议的标准 BT.601 中的系数。
第一步是计算亮度,我们将使用 ITU 建议的常量,并替换 RGB 值。
Y = 0.299R + 0.587G + 0.114B
一旦我们有了亮度后,我们就可以拆分颜色(蓝色色度和红色色度):
Cb = 0.564(B - Y)
Cr = 0.713(R - Y)并且我们也可以使用 YCbCr 转换回来,甚至得到绿色。
R = Y + 1.402Cr
B = Y + 1.772Cb
G = Y - 0.344Cb - 0.714Cr*组织和标准在数字视频领域中很常见,它们通常定义什么是标准,例如,什么是 4K?我们应该使用什么帧率?分辨率?颜色模型?
通常,显示屏(监视器,电视机,屏幕等等)仅使用 RGB 模型,并以不同的方式来组织,看看下面这些放大效果:

色度子采样
一旦我们能从图像中分离出亮度和色度,我们就可以利用人类视觉系统对亮度比色度更敏感的特点,选择性地剔除信息。色度子采样是一种编码图像时,使色度分辨率低于亮度的技术。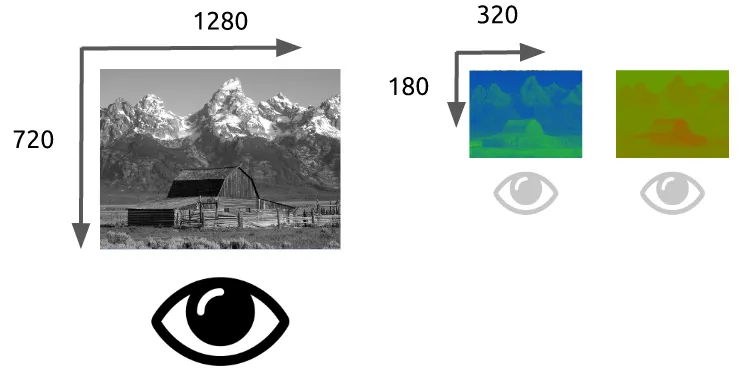
我们应该减少多少色度分辨率呢?已经有一些模式定义了如何处理分辨率和合并(最终的颜色 = Y + Cb + Cr)。
这些模式称为子采样系统,并被表示为 3 部分的比率 - a:x:y,其定义了色度平面的分辨率,与亮度平面上的、分辨率为 a x 2 的小块之间的关系。
a 是水平采样参考 (通常是 4),
x 是第一行的色度样本数(相对于 a 的水平分辨率),
y 是第二行的色度样本数。
存在的一个例外是 4:1:0,其在每个亮度平面分辨率为 4 x 4 的块内提供一个色度样本。
现代编解码器中使用的常用方案是: 4:4:4 (没有子采样), 4:2:2, 4:1:1, 4:2:0, 4:1:0 and 3:1:1。
YCbCr 4:2:0 合并
这是使用 YCbCr 4:2:0 合并的一个图像的一块,注意我们每像素只花费 12bit。
下图是同一张图片使用几种主要的色度子采样技术进行编码,第一行图像是最终的 YCbCr,而最后一行图像展示了色度的分辨率。这么小的损失确实是一个伟大的胜利。

前面我们计算过我们需要 278GB 去存储一个一小时长,分辨率在720p和30fps的视频文件。如果我们使用 YCbCr 4:2:0 我们能减少一半的大小(139GB)*,但仍然不够理想。
* 我们通过将宽、高、颜色深度和 fps 相乘得出这个值。前面我们需要 24 bit,现在我们只需要 12 bit。
分类:
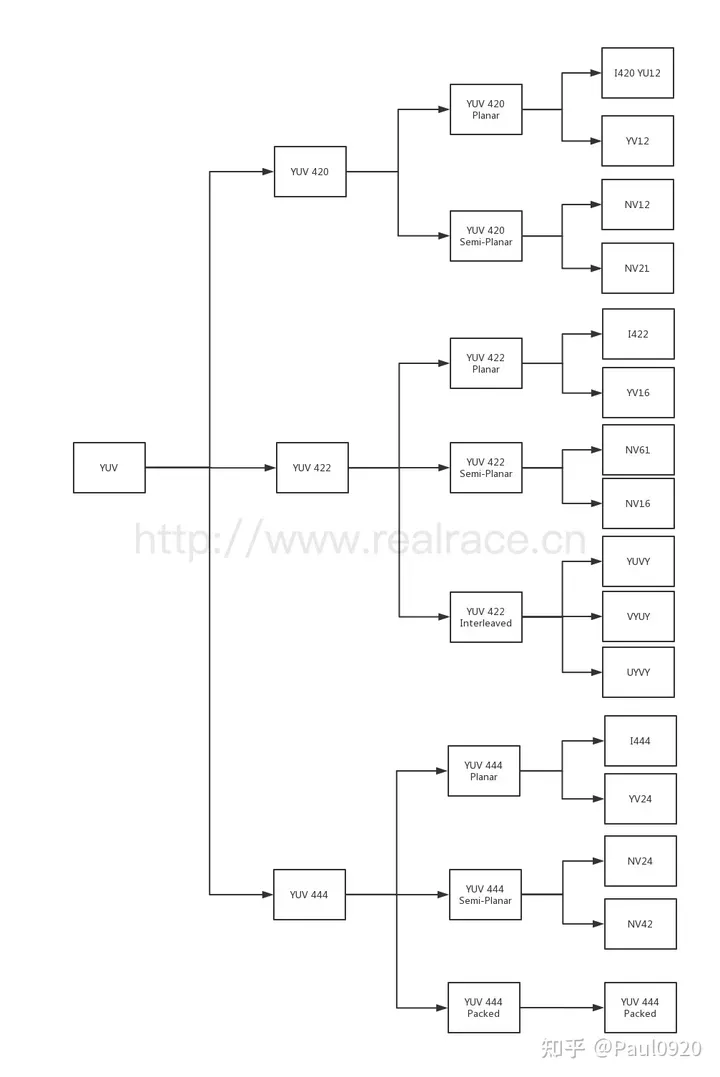
分类标准
首先,我们可以将 YUV 格式按照数据大小分为三个格式,YUV 420,YUV 422,YUV 444。由于人眼对 Y 的敏感度远超于对 U 和 V 的敏感,所以有时候可以多个 Y 分量共用一组 UV,这样既可以极大得节省空间,又可以不太损失质量。这三种格式就是按照人眼的特性制定的。
YUV 420,由 4 个 Y 分量共用一套 UV 分量,
YUV 422,由 2 个 Y 分量共用一套 UV 分量
YUV 444,不共用,一个 Y 分量使用一套 UV 分量
按照多个 Y 分量共用一个 UV 的方式,我们可以把 YUV 分为 420,422,444 三种类型,而在这三种类型之下,我们又可以按照 YUV 的排列储存顺序,将其细分为好多种格式,这些格式数量繁多,又不好记忆,这为我们学习过程中造成了不少困难。下面我就为大家一一介绍。
首先,我们将可以按照 YUV 的排列方式,再次将 YUV 分成三个大类,Planar,Semi-Planar 和 Packed。
Planar YUV 三个分量分开存放
Semi-Planar Y 分量单独存放,UV 分量交错存放
Packed YUV 三个分量全部交错存放
按照这三种方式,我们就可以将 YUV 格式进行比较细致的分类了。
I420: YYYYYYYY UU VV => YUV420P
YV12: YYYYYYYY VV UU => YUV420P
NV12: YYYYYYYY UVUV => YUV420SP
NV21: YYYYYYYY VUVU => YUV420SP采样比
人类视觉系统对亮度(luma)的敏感度高于对色度(chroma)的敏感度,因此可以对色度数据进行下采样;
采样比通常表示为 J:a:b,以表示一个宽为 J 像素、高为 2 像素的采样区域内 Y Cb Cr(Y U V)的采样比:
J 表示采样区域的宽度,通常为 4;
a 表示第一行色度采样数;
b 表示第二行色度采样与第一行色度采样的不同样点数;
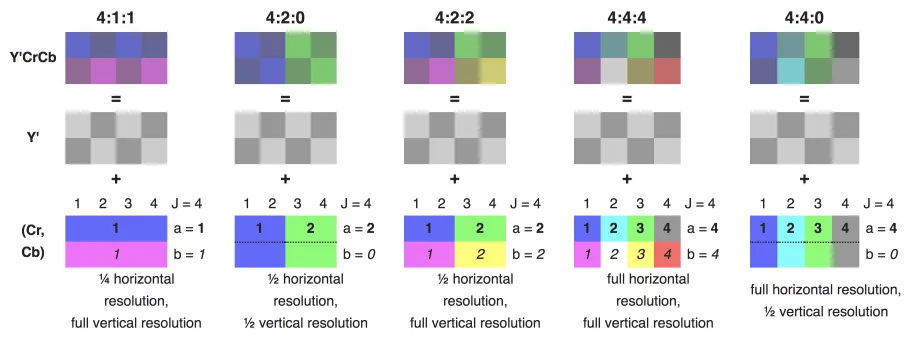
例如上图:
4:1:1:宽度 J 为 4,第一行只有一个样点(一种颜色),所以 a 为 1,第二行和第一行不同的样点只有一个,所以 b 为 1,所以为 4:1:1;
4:2:0:宽度 J 为 4,第一行有两个样点,所以 a 为 2,第二行和第一行样点完全相同,所以 b 为 0,所以为 4:2:0;
这个比例值并非 Y Cb Cr 分量个数的直接比例。对亮度来说,一个样点由一个 Y 构成,而对色度来说,一个样点由两个值构成:Cb 和 Cr。以 4:2:0 为例,在 4x2 的采样区域内,有 8 个亮度样点,2 个色度样点(在上图中可以看成左右各一个),所以有 8 个 Y,2 个 Cb,2 个 Cr。
a 和 b 的取值并非可以随意组合,比如 a 为 2 时,表示第一行有两个样点,如果 b 为 1,那就是说第二行样点有一个和第一行不同,但到底哪一个样点和第一行不同,无法确定,所以这种组合就被禁止了。实际上常见的可取组合也就是上图中列出的五种。
planar, packed 和 semi planar
planar, packed 和 semi planar 是描述分量如何存储的:
planar: 有时也称 triplanar,有三个 plane,每种分量连续存储,先存储所有的 Y 分量,再存储所有的 Cb 分量,最后存储所有的 Cr 分量(也可以 Cr 在前,Cb 在后);
packed: 只有一个 plane,n 个样点的 Y Cb Cr 分量一起存储,接着存储下 n 个样点的分量;n 的取值、其中三种分量的存储方式,也有多种组合;
semi planar: 有两个 plane,先存储所有的 Y 分量,后面 Cb 和 Cr 分量一起存储;
ref:
